Use the Terraform Integration Stage in Spinnaker or Armory Continuous Deployment

Overview of Terraform integration
At the core of Terraform Integration is the Terraformer service, which fetches your Terraform projects from source and executes various Terraform commands against them. When a terraform stage starts, Orca submits the task to Terraformer and monitors it until completion. Once a task is submitted, Terraformer fetches your target project, runs terraform init to initialize the project, and then runs your desired action (plan or apply). If the task is successful, the stage gets marked successful as well. If the task fails, the stage gets marked as a failure, and the pipeline stops.
A Terraform Integration stage performs the following actions when it runs:
- Authenticates to your repo using basic authentication credentials you provide. This can be a GitHub token or a BitBucket username/password combination.
- Pulls a full directory from your Git repository.
- Optionally uses a Spinnaker artifact provider (Github, BitBucket, or HTTP) to pull in a
tfvars-formatted variable file. - Runs the Terraform action you select.
Before you begin
- You have read the Terraform Integration Overview.
- If you are using Armory CD, you have enabled Terraform Integration.
- If you are using Spinnaker, you have installed the Terraform Integration service and plugin (Spinnaker Operator, Halyard)
Example Terraform Integration stage
The following example describes a basic pipeline that performs the plan and apply Terraform actions.
The pipeline consists of these stages:
Plan stage
A Plan stage in a pipeline performs the same action as running the terraform plan command. Although a Plan stage is not strictly required since an Apply stage performs a terraform plan if no plan file exists, it’s a good idea to have one. You’ll understand why during the Manual Judgment stage.
For this stage, configure the following:
- For the Terraform version, pick any version, such as
0.13.3. - For the Action, choose Plan.
- Main Terraform Artifact
- Select Expected Artifact > Define a new artifact
- Select Account >
. This is the Git repo that was configured when you enabled the Terraform Integration and houses your Terraform code. - In URL, add the URL to the Git repo that houses your Terraform code.
- Select Account >
- Select Expected Artifact > Define a new artifact
- Under Produces Artifacts
- Select Define artifact. A window appears.
- Optionally, provide a descriptive display name.
- For Match Artifact > Account , select embedded-artifact .
- Name the artifact
planfile.
The output of this stage, the embedded artifact named planfile, can be consumed by subsequent stages in this pipeline. In this example, this occurs during the final stage of the pipeline. Additionally, more complex use cases that involve parent-child pipelines can also use plan files.
Show stage
The Show stage performs the same action as running the terraform show command.
You can then use the JSON output from your planfile in subsequent stages.
The Show stage depends on the Plan stage. For the Show stage, configure the following:
- For the Terraform version, pick the same version as you did you for the Plan stage.
- For the Action, choose Show.
- For Main Terraform Artifact
- Select Expected Artifact > Artifact from execution context
- Select Account >
. This is the Git repo that was configured when you enabled the Terraform Integration and houses your Terraform code. - In URL, add the URL to the Git repo that houses your Terraform code.
- In Branch, add the branch your code is in.
- Select Account >
- Select Expected Artifact > Artifact from execution context
- For Terraform Plan, add the
planfilefrom the dropdown. This is the artifact you created in the Plan stage. - All other fields can be left blank or with their default values for this example.
You can add an Evaluate Variables stage to get the output from the planfile JSON created by the Show stage and use it in subsequent stages.
- Variable Name:
planfile_json - Variable Value:
${#stage('Show').outputs.status.outputs.show.planfile_json}
Manual Judgment stage
You can use the default values for this stage. Manual judgment stages ask the user to approve or fail a pipeline. Having a Manual Judgment stage between a Plan and Apply stage gives you a chance to confirm that the Terraform code is doing what you expect it to do.
Apply stage
The Apply stage performs the same action as running the terraform apply command. For this stage, configure the following:
- For the Terraform version, pick the same version as you did you for the Plan stage.
- For the Action, choose Apply.
- For Main Terraform Artifact
- Select Expected Artifact > Define a new artifact
- Select Account >
. This is the Git repo that was configured when you enabled the Terraform Integration and houses your Terraform code. - In URL, add the URL to the Git repo that houses your Terraform code.
- Select Account >
- Select Expected Artifact > Define a new artifact
- For Terraform Artifacts, add a new file and select the
planfilefrom the dropdown. This is the file that you created during the Plan stage and verified during the Manual Judgment stage. - All other fields can be left blank or with their default values for this example.
Run the pipeline.
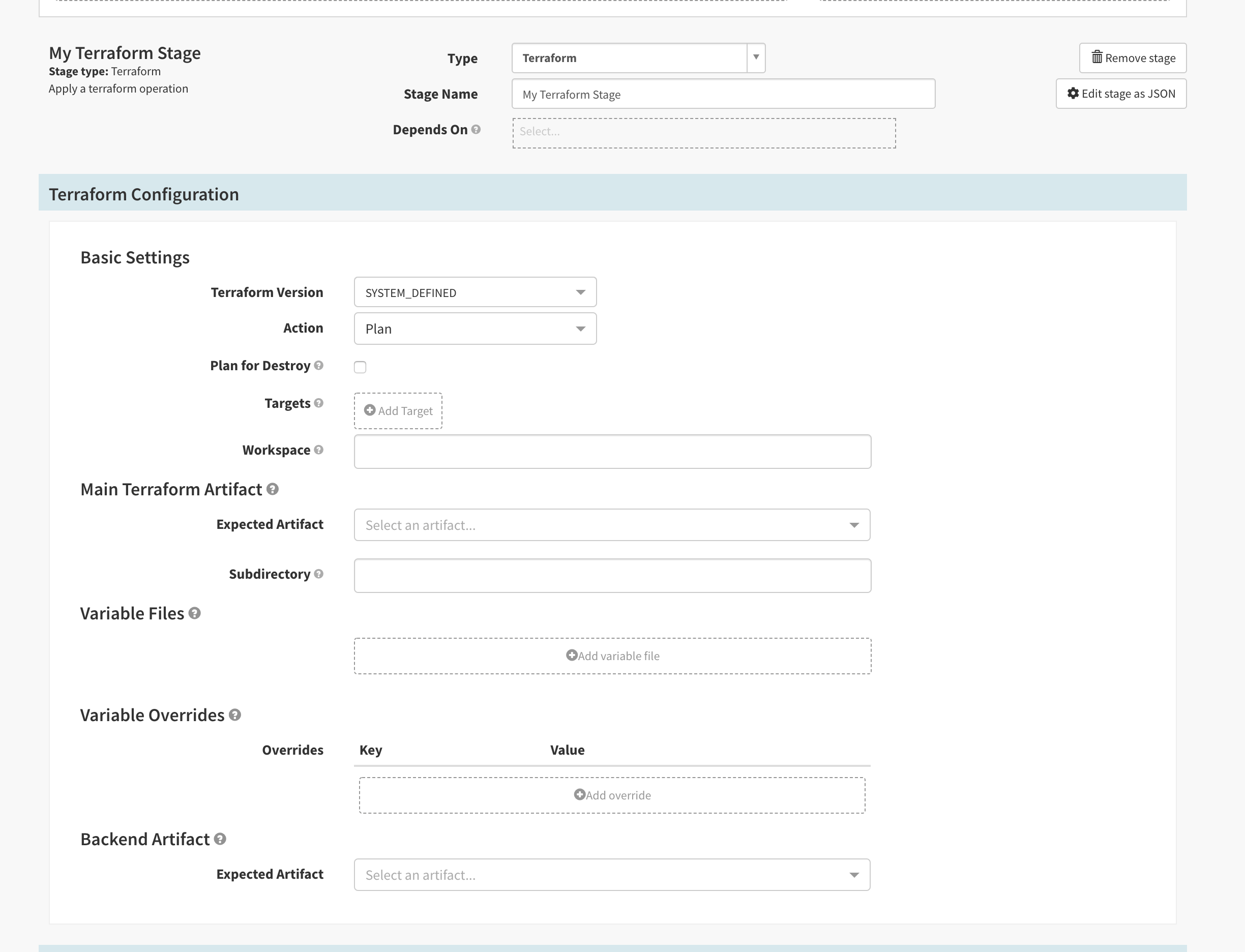
Create a Terraform Integration stage
Configure the RDBMS driver exactly as described in Set up Clouddriver to use SQL - Database Setup. The MySQL database schema must be configured to with:
- Default character set
utfmb4 - Default collate
utf8mb4_unicode_ci
Warning
If the Clouddriver MySQL schema is not configured correctly, the Terraform Integration stage fails.- In Deck, select the Application and pipeline you want to add the Terraform Integration stage to.
- Configure the Pipeline and add a stage.
- For Type, select Terraform.
- Add a Stage Name.
- Configure the Terraform Integration stage.
The available fields may vary slightly depending on what you configure for the stage:
-
Basic Settings
- Terraform Version: Terraform version to use. All Terraform stages within a pipeline that modify state (apply, output, destroy) must use the same version. If you want to use the remote backend, the minimum supported version is 0.12.0 and you must select the same Terraform version that your Terraform Cloud/Enterprise is configured to use.
- Action: Terraform action to perform. You can select any of the following actions:
- Plan: The output of the plan command is saved to a base64-encoded Spinnaker artifact and is injected into context. You can use this artifact with a webhook to send the plan data to an external system or to use it in an
applystage. Optionally, you can select Plan for Destroy to view what Terraform destroys if you run the Destroy action.- For remote backends, if you view a
planaction in the Terraform Cloud/Enterprise UI, the type ofplanaction that the Terraform Integration performs is a “speculative plan.” For more information, see Speculative Plans.
- For remote backends, if you view a
- Apply: Run
terraform apply. Optionally, you can ignore state locking. Armory recommends you do not ignore state locking because it can lead to state corruption. Only ignore state locking if you understand the consequences. - Destroy: Run
terraform destroy. Optionally, you can ignore state locking. Armory recommends you do not ignore state locking because it can lead to state corruption. Only ignore state locking if you understand the consequences. - Output: Run
terraform output. - Show: Run
terraform show. This creates human-readable JSON output from yourplanfile.
- Plan: The output of the plan command is saved to a base64-encoded Spinnaker artifact and is injected into context. You can use this artifact with a webhook to send the plan data to an external system or to use it in an
- Targets: Scope execution to a certain subset of resources.
- Workspace: Terraform workspace to use. The workspace gets created if it does not already exist. For remote backends, the workspace must be explicit or prefixed. For more information about what that means, see the Terraform documentation about remote backends
-
Main Terraform Artifact
-
Expected Artifact: Required. Select or define only one
git/repotype artifact.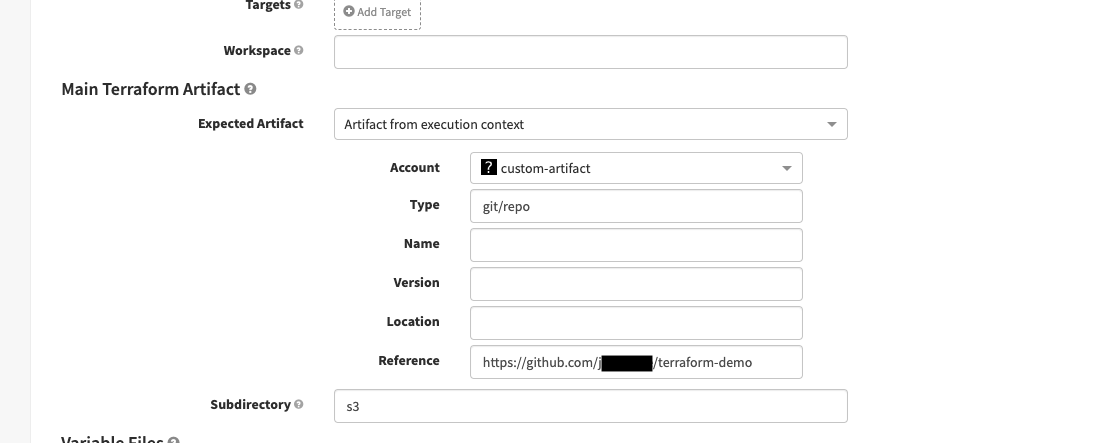
-
Account: The account to use for your artifact.
-
URL: If you use a GitHub artifact, make sure you supply the API URL of the file, not the URL from the
RawGitHub page. Use the following examples as a reference for the API URL:Regular GitHub:
https://api.github.com/repos/{org}/{repo}/contents/{file path}Github Enterprise:
https://{host}/api/v3/repos/{org}/{repo}/contents/{file path} -
Checkout subpath: Enable this option to specify a Subpath within a Git repo. Useful if you have a large repo and the Terraform files are located in a specific directory.
-
Branch: The Git branch or commit to use.
-
-
Subdirectory: Subdirectory within a repo where the
terraformcommand runs. Use./if the command should run at the root level.
-
-
Variable Files: Optional. Variable files that get appended to the Terraform command. Equivalent to running terraform apply with the
-var-fileoption.- If you want to use the output of a Plan stage for an Apply stage, select the Plan stage output as an Expected Artifact
-
Variable Overrides: Optional. Key/value pairs used as variables in the Terraform command. Equivalent to running terraform apply with the
-varoption. You can use a GitHub or BitBucket -
Backend Artifact: Optional. Configuration stored outside of the primary repo that gets used for authenticating to a state backend. For example, if you want to use an S3 artifact for your backend state, specify it in this section.
For the
backendArtifactand other artifacts, you can replacegithub/filewith some other artifact type. For example, if you’re using the BitBucket artifact provider, specifybitbucket/fileand the corresponding artifact account.The Terraform Integration supports remote backends as a feature. Select a Terraform version that is 0.12.0 or higher when configuring the stage. Then, you can use Terraform code that references a remote backend.
-
Custom plugins
Terraform Integration supports the use of custom Terraform providers and plugins. Terraform Integration downloads the plugins and injects them into each stage dynamically as needed to ensure the Terraform code can run.
Any plugin you want to use must meet the following requirements:
- Be a zip, tar, gzip, tar-gzip or executable
- If compressed, be at the root of the archive
- Be x86-64 (amd64) Linux binaries
- Have a SHA256 Sum
- Follow the Terraform plugin naming conventions
Note: If any Terraform Integration stage in a pipeline defines a custom plugin, all Terraform Integration stages must then define that same plugin in the pipeline.
Configuring Terraform plugins:
{
"action": "plan",
"artifacts": [
{
"reference": "https://github.com/someorg/terraformer",
"type": "git/repo",
"version": "refs/heads/branch-testing"
},
{
"metadata": {
"sha256sum": "fda6273f803c540ba8771534247db54817603b46784628e63eff1ce7890994e4"
},
"name": "terraform-provider-foo",
"reference": "https://github.com/armory/terraform-provider-foo/releases/download/v0.1.19/terraform-provider-foo_0.1.19_linux_amd64.zip",
"type": "terraform/custom",
"version": "v0.1.19"
}
],
...
}
Terraform Integration caches all the defined plugins by default and does not redownload them. To configure the Terraform Integration to redownload a plugin, add the following JSON under the metadata key in the artifact object:
"metadata": {
"sha256sum": "longString",
"forceDownload": true,
}
View Terraform log output
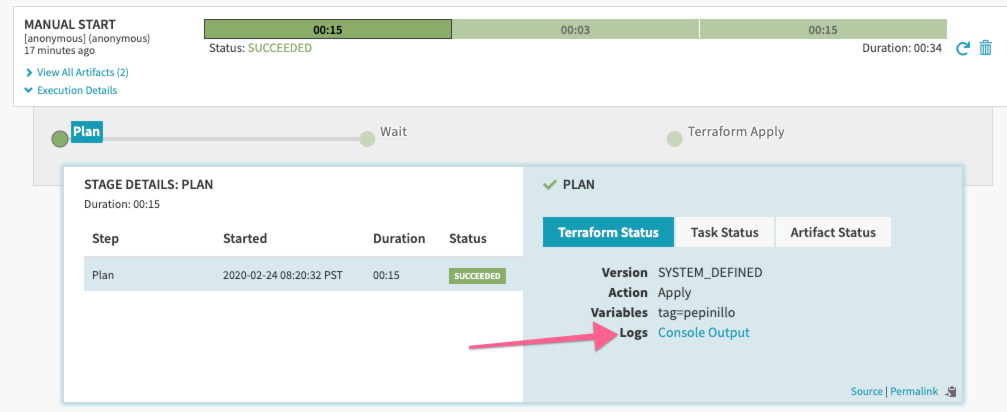
Terraform provides logs that describe the status of your Terraform action. When you run Terraform actions on your workstation, the log output is streamed to stdout. For Armory’s Terraform Integration, Spinnaker captures the log output and makes it available on the Pipelines page of Deck as part of the Execution Details. Exit codes in the log represent the following states:
0 = Succeeded with empty diff (no changes)
1 = Error
2 = Succeeded with non-empty diff (changes present)
For more information about Terraform logs, see the Terraform documentation.
Consume Terraform output using SpEL
If you have a Terraform template configured with Output Values, then you can use the Output stage to parse the output and add it to your pipeline execution context.
For example, if you have a Terraform template that has this:
output "bucket_arn" {
value = "${aws_s3_bucket.my_bucket.arn}"
}
Then you can set up an Output stage that exposes this in the pipeline execution context. If you have an Output stage with the stage name My Output Stage, then after running the Output stage, access the bucket ARN with this:
${#stage('My Output Stage')["context"]["status"]["outputs"]["bucket_arn"]["value"]}
Feedback
Was this page helpful?
Thank you for letting us know!
Sorry to hear that. Please tell us how we can improve.
Last modified October 17, 2023: (aa87b671)